ASP.NET Weblogin Using Python
ASP.NET Weblogin Using Python
ASP.net websites usually send state data in requests and responses in order to keep track of the client’s UI state. An ASP.Net website store the data that you filled out in the previous pages in a hidden field called “__VIEWSTATE”. View State is a Page-Level State Management technique used to preserve the value of the Page and Controls between round trips. It View State is turned on by default and normally serializes the data in every control on the page regardless of whether it is actually used during a post-back.

The __VIEWSTATE information is passed with each POST request that the browser makes to the server and the web server decodes and loads the client’s UI state from this data, performs some processing, computes the value for the new view state based on the new values and renders the resulting page with the new view state as a hidden field.
If the __VIEWSTATE is not properly sent back to the server, a blank form will be displayed as a result because the server completely lost the client’s UI state. In order to crawl pages resulting from ASP.net forms like this, we haveto make sure that the crawler is sending __VIEWSTATE data with its requests, otherwise the page will not load as expected.
Here, the python script tries to simulate the browser actions to login to an ASP.net website. BeautifulSoup is used to scrap the the webpage to gather required information.
In this website, once the website login page is accessed a dynamic url is generated for entering login information.
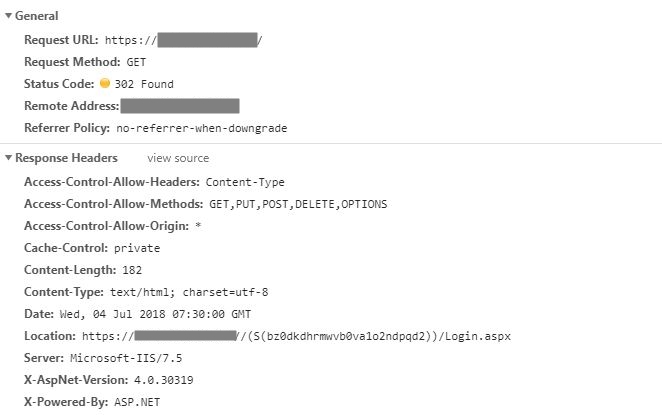
New URL is present in the Response Header
![]()
Building your Spider
The steps that the spider should follow to simulate the browser action
from bs4 import BeautifulSoup
import requests
session = requests.Session()
r = session.get('http://www.demohost.com/')
print ("STATUS 1:",r.status_code)
print (r.history)
print ("REDIRECT 1: ",r.url)
loginpage = session.get(r.url)
soup = BeautifulSoup(loginpage.text,"html.parser")
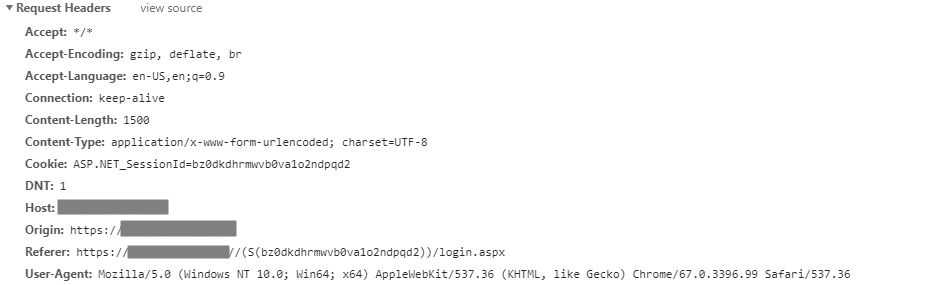
Next is to build the request data with necessary information required for POST request to the web server. Enable and inspect the browser debugger for required information for your weblogin.

Request Header information. In this example we are passing only the referer value in Header data.
# parse and retrieve two vital form values
viewstate = soup.select("#__VIEWSTATE")[0]['value']
eventvalidation = soup.select("#__EVENTVALIDATION")[0]['value']
item_request_body = {
"__EVENTTARGET":"",
"__EVENTARGUMENT":"",
"__VIEWSTATE":viewstate,
"ASPxRoundPanel1$UserEdit":"username",
"ASPxRoundPanel1$PassEdit":"password",
"CookieWarning":"{"collapsed":false}",
"DXScript":"1_225,1_130,1_218,1_164,1_162,1_170,1_151,1_169,1_127,1_207,1_215,1_128,1_199",
"DXCss":"0_277,1_32,0_279,1_18,0_114,0_112",
"__CALLBACKID":"usercb",
"__CALLBACKPARAM":"c0:Login:userdata:userdata",
"__EVENTVALIDATION":eventvalidation
}
print("VIEWSTATE : ",viewstate)
print("EVENTVALIDATION : ",eventvalidation)
POST operation
A Session POST request is invoked with the url, data and header parameters. __VIEWSTATE and __EVENTVALIDATION information is stored in item_request_body. After successful login, the contents of the home page will stored in defaultpage variable.
print ("==========POST==============")
response = session.post(url=r.url, data=item_request_body, headers={"Referer": r.url})
print ("STATUS 2:",response.status_code)
defaultpage = r.url[:-10]+"form_custom.aspx?param1=ASR¶m2=New¶m3=default"
print ("PAGE : ", defaultpage)
page = session.get(defaultpage)
print (page.content)